fuzz入门到入土(二)
LibFuzzer学习(一):轻松找到心脏出血漏洞
和AFL的区别在于LibFuzzer可以直接在进程中尝试输入数据,而AFL多的在于从外部将变异数据传入被测试程序内部。
libFuzzer demo
demo解析
1 |
|
这个程序非常简单,首先看一下FuzzMe()函数。接收参数主要有两个,一个是字符串Date,另一个是字符串长度DateSize。如果字符串长度大于3,且Data中数据前5个字节为le0n.则返回1,如果上述中一项不满足则返回0
然后,一般的C++程序都会存在一个main()函数作为入口,但是在这个demo中main()函数被LLVMFuzzerTestOneInput()函数取代了,这是因为libfuzzer需要在进程内为程序提供了输入参数,libfuzzer库内部存在main()函数,这样一来libfuzzer可以自由控制输入,因此在使用libfuzzer时,需要使用LLVMFuzzerTestOneInput()函数来代替main()函数作为执行入口
编译目标程序
目标程序需要使用clang进行编译,libFuzzer的代码覆盖率也是有LLVM内部工具提供的,如果一下载最新版的clang编译器(版本>6.0),就可以直接使用libFuzzer,无需额外安装
目标程序需要使用 clang 进行编译,libFuzzer 的代码覆盖率信息也是由 LLVM 内部工具提供了,如果你已经下载了最新版的 clang 编译器(版本 > 6.0),就可以直接使用 libFuzzer,无需额外安装。
在 clang 编译和链接时,可以使用 -fsanitize=fuzzer 标志启用 libFuzzer,这个参数时必须使用的,为了告知 libFuzzer 库准备进行链接,同时也可以结合 AddressSanitizer (ASAN)、UndefinedBehaviorSanitizer (UBSAN)、MemorySanitizer (MSAN) 一起使用:
1 | clang -g -fsanitize=fuzzer demo.c # 直接构建 fuzz 目标文件 |
那么回到上面的 demo 中,由于它是一个 C++ 程序,所以这里选用 clang++ 进行编译:
1 | clang++ -O0 -g -fsanitize=fuzzer,address ./demo.cc -o demo |
这里在我的ubuntu22.04上编译时要用O0,不能用O1,如下:
使用 -O0(无优化):
assembly
1 | # 编译器为每个条件生成独立的基本块 |
使用 -O1(中等优化):
1 | # 编译器可能合并条件,减少分支 |
O1会让编译器在编译过程中进行优化(采用&&的短路原理减少内存块的分配)。这样一来就得到了编译好的程序 demo。
fuzz过程及日志解析
由于libFuzzer是与程序源码一起进行编译的,所以无需再程序外部做其他的配置,直接运行编译后的程序demo将会看到下面的日志结果:
1 | le0n:demo1/ $ ./demo_O0 |
种子seed
1 | INFO: Seed: 3203650924 |
这里在程序执行时会生成一个seed随机种子,
输入大小
1 | INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes |
这里提示没有指定-max_len参数,所以libFuzzer默认4096字节作为最大输入字节,并且提示没有指定一个语料库
覆盖率情况
1 | #2 INITED cov: 3 ft: 3 corp: 1/1b exec/s: 0 rss: 30Mb |
这段信息就是libFuzzer覆盖率情况,这里表示libFuzzer至少运行了7109次(#7109),共发现10个字节中的4给输入字节(4/10b),共覆盖了6个基本块(cov:6)
漏洞类型
后面就是ASan的日志信息了:
1 | ==15295==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x6020000432d3 at pc 0x64fd57ae6f2e bp 0x7ffc3abb1d20 sp 0x7ffc3abb1d18 |
在上一篇文章中以及讲述了ASan的结果怎么看,这里就不赘述了。
crash 文件
1 | artifact_prefix='./'; Test unit written to ./crash-10a45a293f07e88f3b4651bcfc0dd2cf6cb6a162 |
在日志最后会告知崩溃POC存放在当前目录,名称crash-10a45a293f07e88f3b4651bcfc0dd2cf6cb6a162
演示Heartbleed(心脏滴血)漏洞
小插曲,如何高效的下载github仓库中的一个文件夹
这是最现代、最“根正苗红”的 Git 官方方法。它允许你先克隆一个“空”的仓库结构,然后只拉取你指定的文件夹内容。
优点:
- 是 Git 的原生功能,功能强大。
- 后续如果想拉取其他文件夹或者更新,操作也很方便。
步骤:
- 克隆一个“空”仓库
打开终端,运行以下命令。这会克隆仓库的元数据,但不会检出(下载)任何文件。
--filter=blob:none: 告诉 Git 不要下载任何实际的文件内容 (blobs)。--no-checkout: 克隆后不要将文件检出到工作目录。
- 进入仓库目录
- 指定你想要的文件夹
这是最关键的一步。使用sparse-checkout命令告诉 Git 你只需要openssl-1.0.1f。
- 检出文件
现在,Git 会自动从远程仓库只下载并检出你指定的那个文件夹。
(在新版本的 Git 中,上一步的set命令通常会自动触发检出。如果执行完上一步后文件夹没出现,可以手动执行git checkout。)现在你的
fuzzer-test-suite目录里就只会有openssl-1.0.1f这一个文件夹了。
这里多此一举了,还是需要把整个仓库clone下来的
1 | le0n:demo1/ $ git clone https://github.com/google/fuzzer-test-suite |
Heardbleed 漏洞是在 2014 年发现的 OpenSSL 加密库中的一个严重漏洞,漏洞编号:CVE-2014-0160。该漏洞可以通过模糊测试的方式快速找到,在 Google 提供的 fuzzer-test-suite 项目中可以找到存在 heartbleed 漏洞的 openssl-1.0.1f 版本。
build 和 target 说明
将 fuzzer-test-suite 项目下载后,首先进入 openssl-1.0.1f 目录查看一下都有什么:

这里主要有两个文件build.sh和target.cc,首先看一下build.sh中的内容
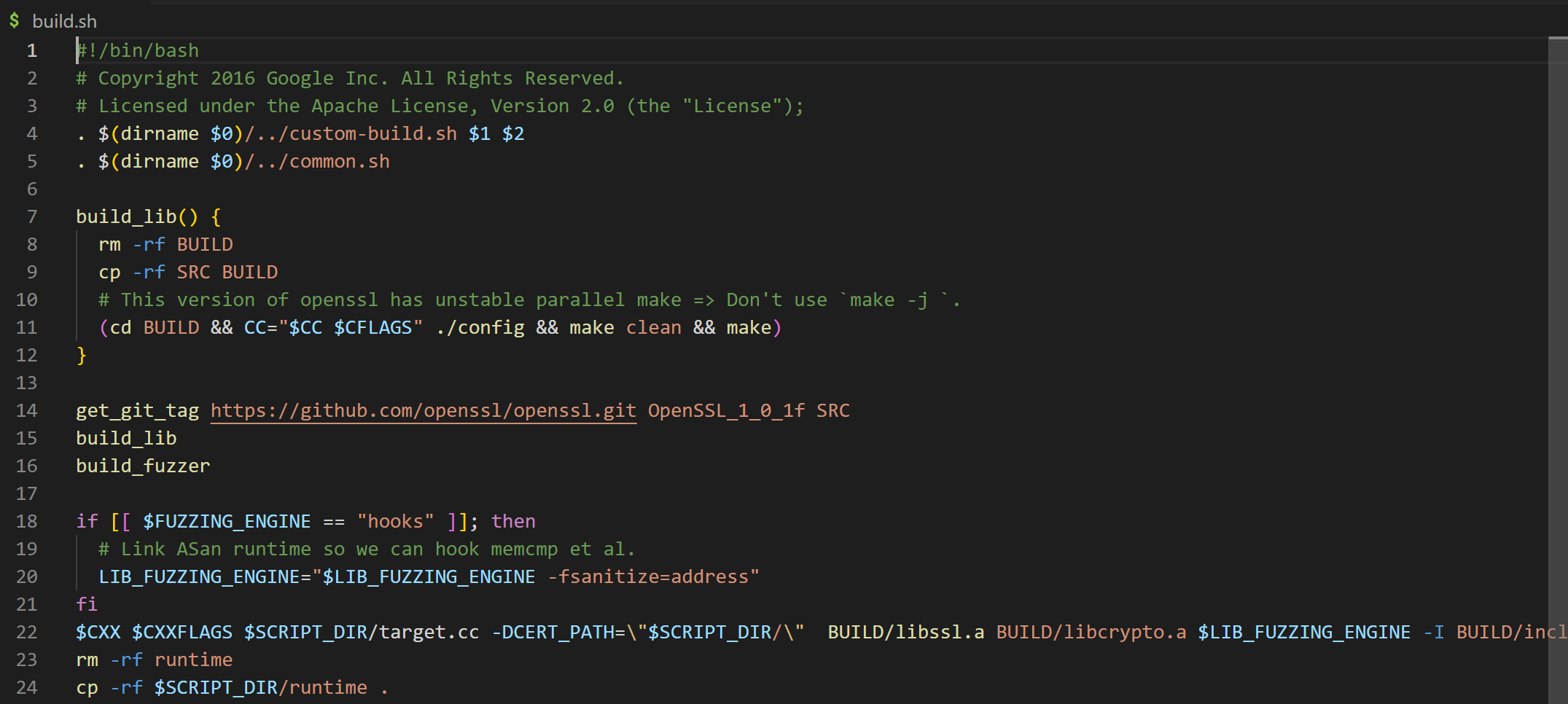
build.sh中主要作用在于从git中拉取OpenSSL_1_0_1f版本源码放在当前路径下的SRC文件夹中,并在当前路径下创建BUILD文件夹,将SRC中的内容复制到BUILD中,接下来编译安装openssl。接下来利用libfuzzer和asan编译target.cc程序。最后将runtime文件夹下的公司钥复制到当前路径下的runtime中,接下来看target.cc:
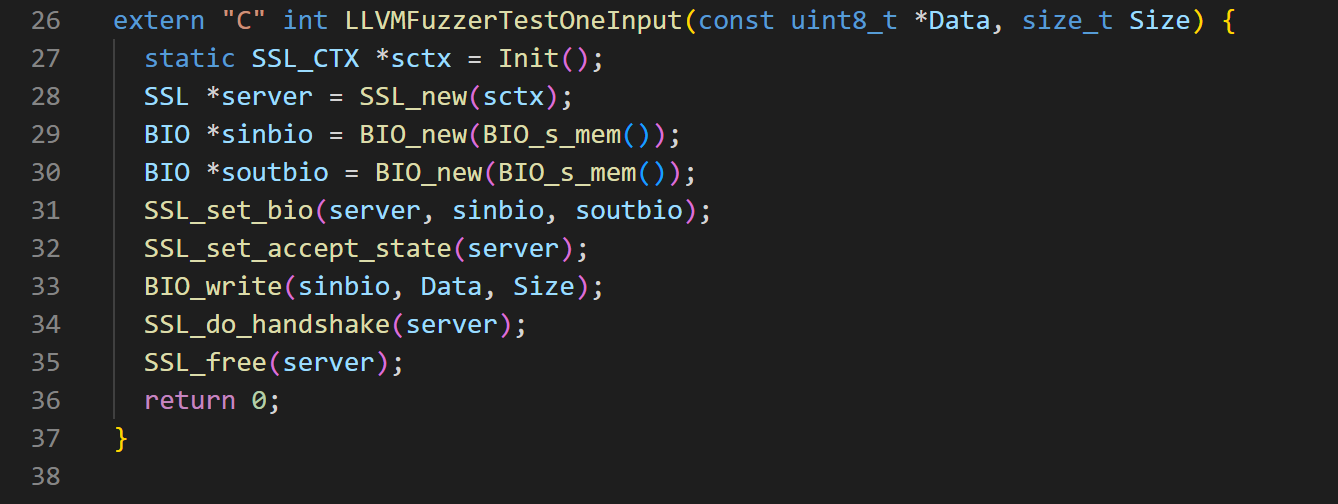
这里解释一下程序执行流程图,图中进阶去主函数部分,前面为Init()函数中的部分,主要进行openSSL初始化连接公私钥等内容。下面使用libfuzzer的LLVMFuzzerTestOneLnput()函数代替main()函数,看一下内部情况:
- 28:建立SSL连接
- 29、30:创建内存型BIO输入参数sinbio和soutbio
- 31:设置SSL的获取和发送
- 32:将SSL设置为在服务器模式下工作
- 33:尝试将Size个字节从Data中写入BIO sinbio(Data内容和Size数量来自libfuzzer编译内容)
- 34:等待SSl/TLS握手
- 35:释放内存
编译target文件
这里由于build.sh中已经编辑好了编译流程,所以我在我的demo1目录下创建一个heartbleed目录来直接运行build.sh:
1 | le0n:demo1/ $ cd heartbleed |
运行结束后就可以看到编译好的openssl-1.0.1f-fsanitize_fuzzer

执行fuzz
接下来直接运行程序openssl-1.0.1f-fsanitize_fuzzer,由于libfuzzer在编译的时候就加入了源码,所以直接运行就开始跑了
1 | le0n:heartbleed/ $ ./openssl-1.0.1f-fsanitize_fuzzer [14:23:40] |
可以看到 libfuzzer 在执行 100362 次后,共发现 2905b 中的 76 个输入项,覆盖 639 个基本块。后面 ASan 日志判定漏洞类型为 堆溢出,溢出执行位置pc、bp、sp分别在 0x629000009748、0x7fffa8b90770、0x7fffa8b8ff40。shadow 图中演示数据已经溢出到相邻高地址堆块的头部,fuzz过程中造成的crash已经保存在当前目录crash-ea955891f4388f1bf936c9f824c5081c1cd85a03。后续可以用 gdb 验证一下。
就先这样,下一篇写优化~
gdb验证
使用 GDB 来验证和深入分析 Fuzzing 发现的崩溃是一个非常专业且有效的做法。它能让你从“程序崩溃了”的层面,深入到“程序为什么会以及如何在这里崩溃”的层面。
您看到的 Kali 上的文章,通常是使用现成的漏洞利用(Exploit)脚本,例如专门的 Python 脚本或 Metasploit 模块。这些工具的目的是利用漏洞,即从一个正在运行的、有漏洞的服务中窃取数据。
而我们使用 GDB 的目的不同,是为了调试和分析,即在本地重现崩溃,并观察程序在崩溃前的内存和变量状态,从而从根本上理解漏洞的成因。
下面,我将为您提供一个详细的、分步的 GDB 验证指南。
核心思路
ASan 在发现越界读取的瞬间就中止了程序,这很好,但它也阻止了我们观察“数据被完整拷贝出来”这个后续行为。为了在 GDB 中清晰地观察到数据泄露,我们需要一个没有 ASan但带有调试信息的可执行文件。
第一步:重新编译一个用于 GDB 调试的版本
这是最关键的一步。我们需要关闭 ASan,但开启 -g 标志来保留调试符号(函数名、行号等)。
回到构建目录:
1
2# 假设您还在 heartbleed 目录下,先回到 fuzzer-test-suite 的根目录
cd ../fuzzer-test-suite/修改构建脚本(临时):
我们需要编辑common.sh文件,去掉-fsanitize相关的标志。1
2# 打开 common.sh 文件
nano common.sh找到下面这两行(或类似的行):
1
2export CFLAGS="$CFLAGS -fsanitize=address,fuzzer-no-link"
export CXXFLAGS="$CXXFLAGS -fsanitize=address,fuzzer-no-link"在它们前面加上
#,将它们注释掉。然后添加新的、只包含-g的行:1
2
3
4# export CFLAGS="$CFLAGS -fsanitize=address,fuzzer-no-link"
# export CXXFLAGS="$CXXFLAGS -fsanitize=address,fuzzer-no-link"
export CFLAGS="$CFLAGS -g"
export CXXFLAGS="$CXXFLAGS -g"保存并退出 (
Ctrl+X,Y,Enter)。重新构建:
现在,我们再次运行build.sh来生成一个带调试信息的新版本。1
2cd openssl-1.0.1f/
./build.sh构建完成后,在
fuzzer-test-suite/out/目录下会有一个新的openssl-1.0.1f可执行文件。这个文件就是我们用来 GDB 调试的目标。注意: 调试完成后,记得把
common.sh文件改回去,以便将来继续进行 Fuzzing。
第二步:使用 GDB 启动并分析
现在,我们有了可执行文件 (out/openssl-1.0.1f) 和导致崩溃的输入文件 (crash-ea955891...)。
启动 GDB:
使用--args参数来告诉 GDB 程序的命令行参数是什么。1
2
3# 确保你在 fuzzer-test-suite 目录下
# 把 crash-ea95... 换成你实际的文件名
gdb --args ./out/openssl-1.0.1f ./openssl-1.0.1f/crash-ea955891f4388f1bf936c9f824c5081c1cd85a03设置断点:
根据之前的 ASan 报告,我们知道漏洞的关键函数是tls1_process_heartbeat。我们就在这个函数的开头设置一个断点,这样程序一进入这个函数就会停下来。1
2(gdb) b tls1_process_heartbeat
Breakpoint 1 at 0x...: file ssl/t1_lib.c, line 2508.运行程序:
1
(gdb) run
程序会开始执行,然后停在我们设置的断点处。
检查关键变量 (核心步骤):
心脏滴血漏洞的核心是程序相信了客户端发来的长度字段。在tls1_process_heartbeat函数中,有两个关键变量:p: 一个指向心跳请求负载开头的指针 (unsigned char *)。payload: 从请求中读取到的负载长度 (unsigned int)。
让我们打印出这两个变量的值。
1
2
3
4
5
6
7
8# 打印 payload 变量的值
(gdb) p payload
$1 = 65535 # 你可能会看到一个很大的数字,比如 65535 或其他
# 打印 p 指向的内存内容(也就是实际的 payload)
# x/16xb p 的意思是:以 16 进制、字节为单位,显示 p 指针后的 16 个字节
(gdb) x/16xb p
0x...: 0x18 0x03 0x01 0x00 0x01 0x01 0x02 0x03 ...分析:
此时你会看到一个巨大的矛盾:payload的值非常大(比如几万),但p指针指向的实际数据非常短。Fuzzer 正是构造了这样一个畸形的数据包!观察
memcpy行为:
现在,我们单步执行,直到找到那个致命的memcpy。- 不断输入
n(next) 来执行下一行代码。 - 你会找到类似下面这行代码:这里
1
memcpy(bp, pl, payload);
bp是目标缓冲区,pl是源(和我们之前看的p差不多),而payload就是那个被我们信任了的、巨大的长度。
- 不断输入
见证数据泄露:
- 在
memcpy执行前,我们先看一下目标缓冲区bp里的内容。它可能是空的,也可能是一些垃圾数据。1
(gdb) x/64xb bp
- 执行
memcpy: 输入n,让这行memcpy执行完毕。由于没有 ASan,程序现在不会崩溃,而是会忠实地执行这个越界读取! - 在
memcpy执行后,我们再次检查bp缓冲区的内容。你会看到,1
(gdb) x/64xb bp
bp缓冲区现在不仅包含了原始的那一小段 payload,后面还跟了一大串从其他内存区域复制过来的数据!这些紧跟在原始数据包后面的、本不应该被读取的数据,就是“心脏滴血”泄露出来的信息。
- 在
退出 GDB:
1
(gdb) quit
总结
通过 GDB,您亲眼见证了心脏滴血漏洞的完整过程:
- 程序接收到一个长度字段与实际数据大小不符的恶意心跳包。
- 程序盲目信任了这个长度字段。
- 在
tls1_process_heartbeat函数中,程序调用memcpy,试图复制这个超长的数据。 memcpy越过了原始数据包的边界,将相邻内存中的敏感数据一并复制到了用于响应的缓冲区中。- 这些数据最终会被发回给攻击者,造成严重的信息泄露。
这个过程比单纯看 ASan 报告要直观得多,它让你真正理解了为什么一个缓冲区溢出(Buffer Overflow)会导致一个信息泄露(Information Disclosure)漏洞。
LibFuzzer学习(二):提高代码覆盖率和速度
前言
前一篇文章中展示了 libfuzzer 的基本用法,在实际的 模糊测试 过程中,仅仅使用基本的用法会消耗非常多的时间,也会因为代码覆盖率不足的原因导致找不到想要的漏洞。这就需要通过一些技巧来提升代码覆盖率和速度。
指定seed corpus提高代码覆盖率
这里我们拿 Google 的 woff2 进行举例,可以在 fuzzer-test-suite 项目中找到 woff2-2016-05-06 项目的 build 文件,该项目主要用于利用 brotli 压缩算法压缩 woff2 格式字体。
本次实验重点在于比较使用 seed corpus 前后代码覆盖率差别,以及提高代码覆盖率带来的好处。
这里首先简单的介绍一下本次实验 woff2-2016-05-06 目录下的两个重要文件,一个是 build.sh,另外一个是 target.cc。首先看 build.sh 文档。
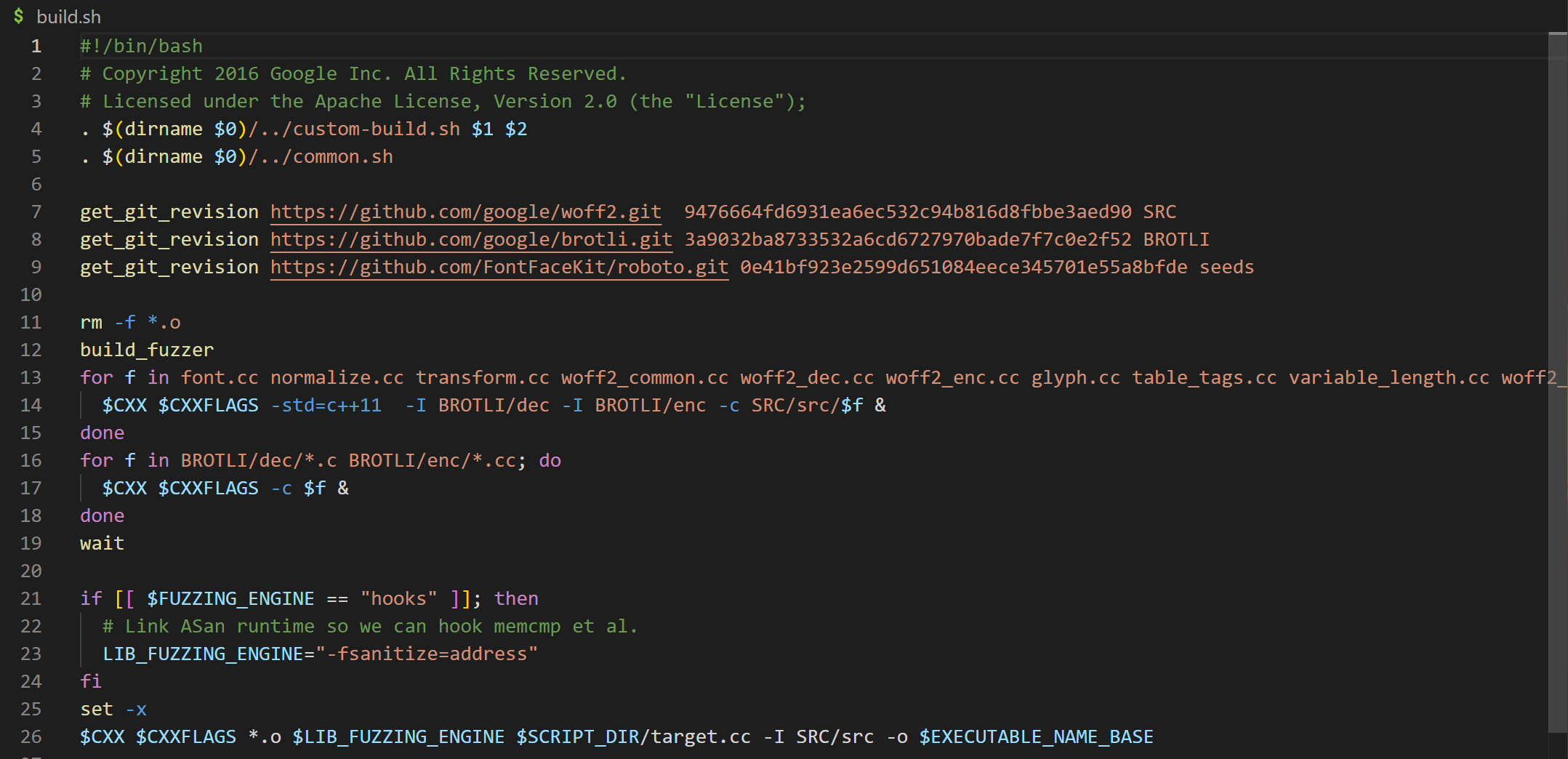
- 7、8、9 行:将 woff2、brotli、roboto 项目分别下载到当前目录的
SRC、BROTYLI、seeds文件夹中。 - 13-15 行:添加目录包括
BROTLI/de和BROTLI/enc搜索路径,循环换个编译font.cc、normalize.cc、transform.cc、woff2_common.cc、woff2_dec.cc、woff2_enc.cc、glyph.cc、table_tags.cc、variable_length.cc、woff2_out.cc文件。 - 16-18 行:编译
BROTLI/de和BROTLI/enc路径下所有源文件。 - 26 行:启用
LibFuzzer和ASAN编译target.cc文件。
接下来看看 target.cc 文件。
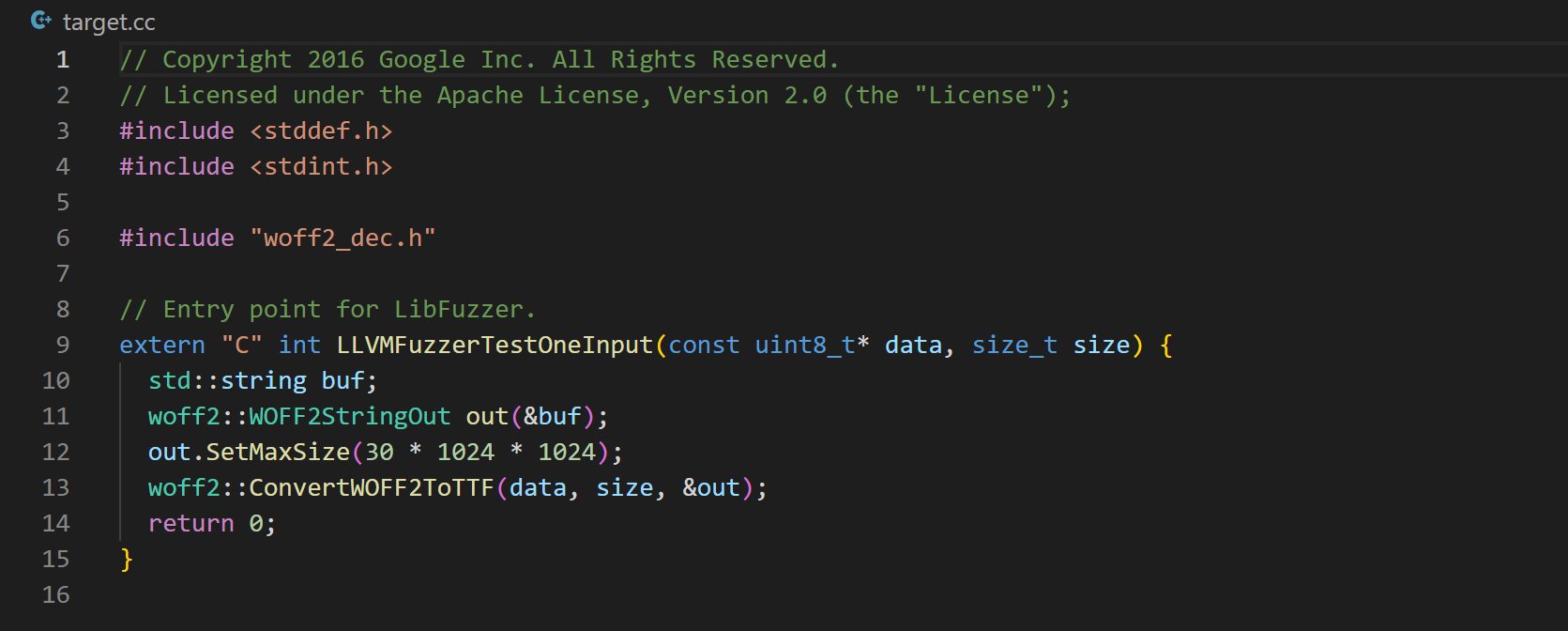
target.cc 文件中的内容是比较简单的,使用 LLVMFuzzerTestOneInput 代替程序中原本的 main 函数,借助 LibFuzzer 可以再程序内部提供输入,主函数中关键函数为 woff2::ConvertWOFF2ToTTF(),将 Woff2 格式文件转换成 TTF 格式文件,参数 data 和 size 由 LibFuzzer 提供传入。 接下来在创建一个文件夹,并运行 build.sh:
1 | le0n:libFuzzer/ $ mkdir demo2 |
运行后,将会看到编译成功的可执行文件 woff2-2016-05-06-fsanitize_fuzzer,以及编译好的各项库文件。
正常使用libfuzzer
正常使用libfuzzer只需要运行一下./woff2-2016-05-06-fsanitize_fuzzer,接下来看libfuzzer和ASan的日志
1 | le0n:demo2/ $ ./woff2-2016-05-06-fsanitize_fuzzer |
可以看到 LibFuzzer 尝试执行了 13937934 次,发现了 21kb 个字节中 318 个输入字节,覆盖 624 个代码块,最后检查到的结果仅仅是一个 OOM。 OOM样例存储在当前目录下 oom-93c3659d17d213c13cac023c5d0dbf9f538de819。
这里其实是有一些问题的,一般即使是轻量级运行库,代码覆盖率只达到 624,实际上是有点少的。这是因为启动 LibFuzzer 的时候仅仅通过自带的 seed 进行变化,即使消耗了大量的内存,也不能在规定时间内找到新的 path。
指定seed corpus再次执行libfuzzer
在上面build.sh文件中,其实已经下载好了一些seed,存放在当前目录的seeds文件夹中:
1 | le0n:demo2/ $ ls seeds |
其中有很多的文件可以作为本次模糊测试的seed corpus,所以系欸笑傲了就可以创建一个文件夹,每次编译后的输入会保存到这个文件夹中。
1 | le0n:demo2/ $ mkdir out |
这样就制定了seed corpus,并将每次编译后的输入保存到out文件夹中。看一下输出日志:
1 | le0n:demo2/ $ ./woff2-2016-05-06-fsanitize_fuzzer ./out ./seeds [15:55:38] |
根据日志可以看到本次fuzz载入了seeds目录下的62个文件,共尝试了4968156次共发现56MB字节中的906个输入字节,共覆盖1048个基本快。并且发现了一个堆溢出漏洞。crash结果存放在当前目录的crash-558d58bf06923fd30cba47a6817c123332a79f6
对比未使用seed corpus时的覆盖情况:


可以看到在使用seed corpus后libfuzzer在尝试次数减少的同时,代码覆盖率相比之前提高了424个基本块。这也导致了libfuzzer发现了新路径中的堆溢出路径
也可以在out文件夹中看到每次变异后的数据:

嗯,非常之多
使用多核并行fuzz
和AFL一样,LibFuzzer也提供使用多核并行fuzz。每个LibFuzzer进程都是单进程,但是可以在seed corpus目录中并行开启多个LibFuzzer进程,这样来一个fuzzer进程找到的任何新输入都可以为其他fuzzer进程提供帮助。
可以使用 -jobs=N 参数进行设置,这里需要注意的是 N 并不代表使用的核心,而是设定的 fuzzing job。LibFuzzer在指定-jobs参数后,这些fuzzing job将会由 worker 进行处理,worker数量默认认为是CPU核心数的一半。这是举个例子,-job=40 在16核心上运行,默认会执行8个worker处理40个fuzzing job,当其中一个worker完成已分配的fuzzing job后,将会从剩下的32个fuzzing job中再分配一个job给worker。
还是用woff2进行举例,指定 -jobs=8(服务器 16 核):
1 | ./woff2-2016-05-06-fsanitize_fuzzer -jobs=8 out/ seeds/ |
由于我的wsl2可以使用主机的16核,所以LibFuzzer会启用8个worker来处理这8个fuzzing job,每个worker处理的结果日志会分别放在当前目录下 fuzz-0~7.log 文件中。可以看到job 2首先发现了一个崩溃的时间。
在之前未使用并行,但使用seed corpus进行模糊测试,出现崩溃所用的时间大概是 15分钟左右。本次由于使用seed corpus和并行执行,发现一次发现崩溃的时间 不到2分钟。
8个worker执行日志及跑出来的crash结果将会在当前路径下看到(我提前中断了):

字典
另外一种提升速度的方式就是使用字典辅助进行模糊测试,可以在被测试程序执行时添加 -dict=dictionaries_path。
测试项目构建
这里选择之前使用AFL++测试的libxml2项目进行举例。同时,可以在fuzzer-test-suite项目中找到对应的项目build路径(fuzzer-test-suite/libxml2-v2.9.2/),其中比较重要的文件有两个:build.sh 和 target.cc。这是先看一下一下 build.sh。
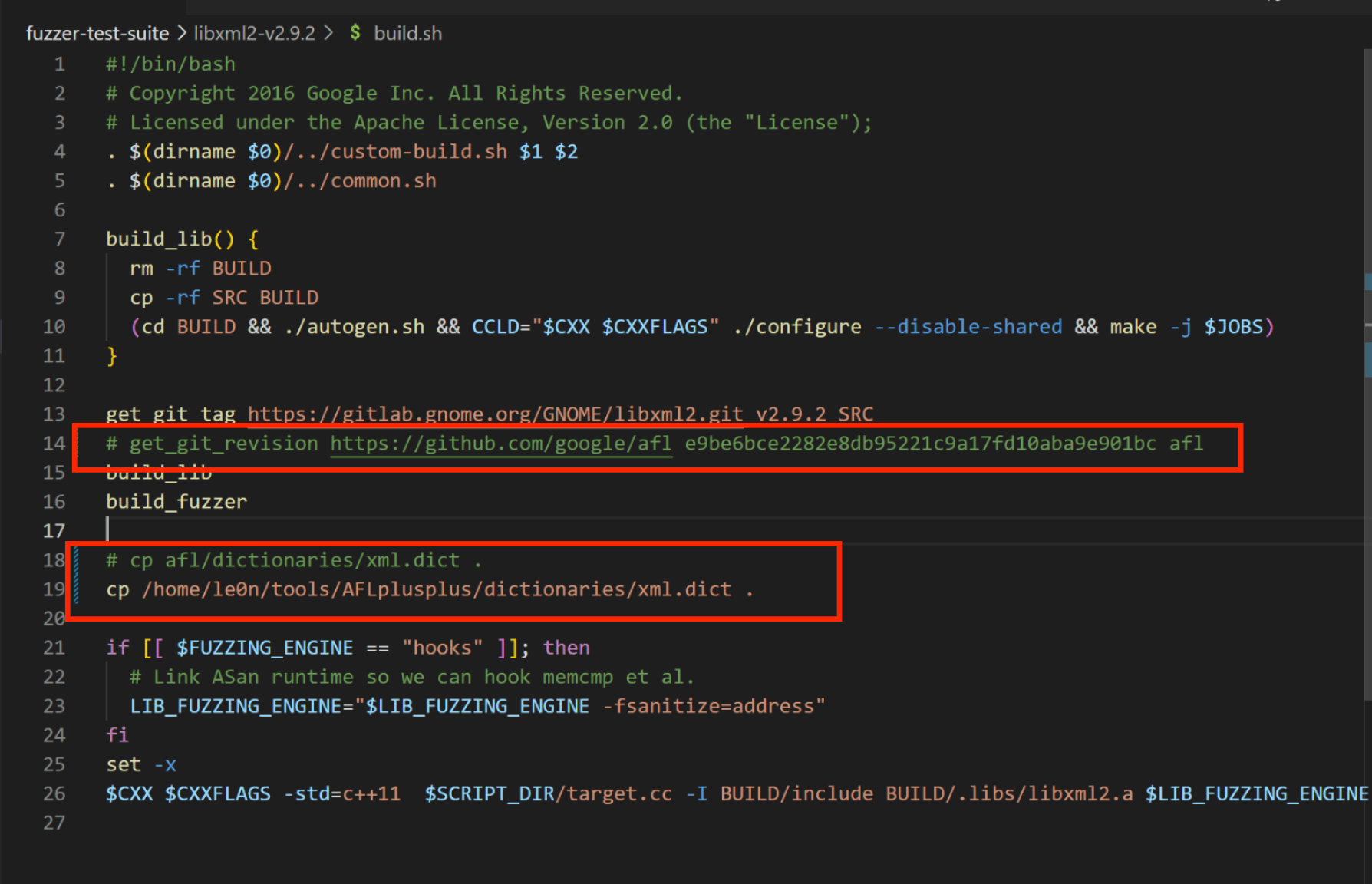
这个 build.sh 脚本我做了一些小的改动,下面稍微做一下分析:
- 13行:将2.9.2版本的libxml2下载到当前目录的SRC文件夹中。
- 14行:这里做了第一次更改,源脚本中这里下载了一个AFL,目的是为了用AFL项目中的xml.dict字典,因为我的虚拟机里本来就有AFL++,在字典目录中同样有这个字典,所以就把这里给注释掉了。当然如果你的环境中没有AFL或AFL++也可以不把这里注释掉,或者注释掉后单独下载自己习惯用的字典。
- 15, 7~11行:这里主要是构建libxml2,将项目源代码拷贝到BUILD目录中进行编译。
- 18, 19行:这里是第二个修改的小地方,原来是将AFL字典目录下的xml.dict拷贝到当前目录,前面也说了,本身环境中AFL++的字典。
- 21~26行:使用LibFuzzer变量导入target.cc程序。
接下来看看一下 target.cc 内部程序流:
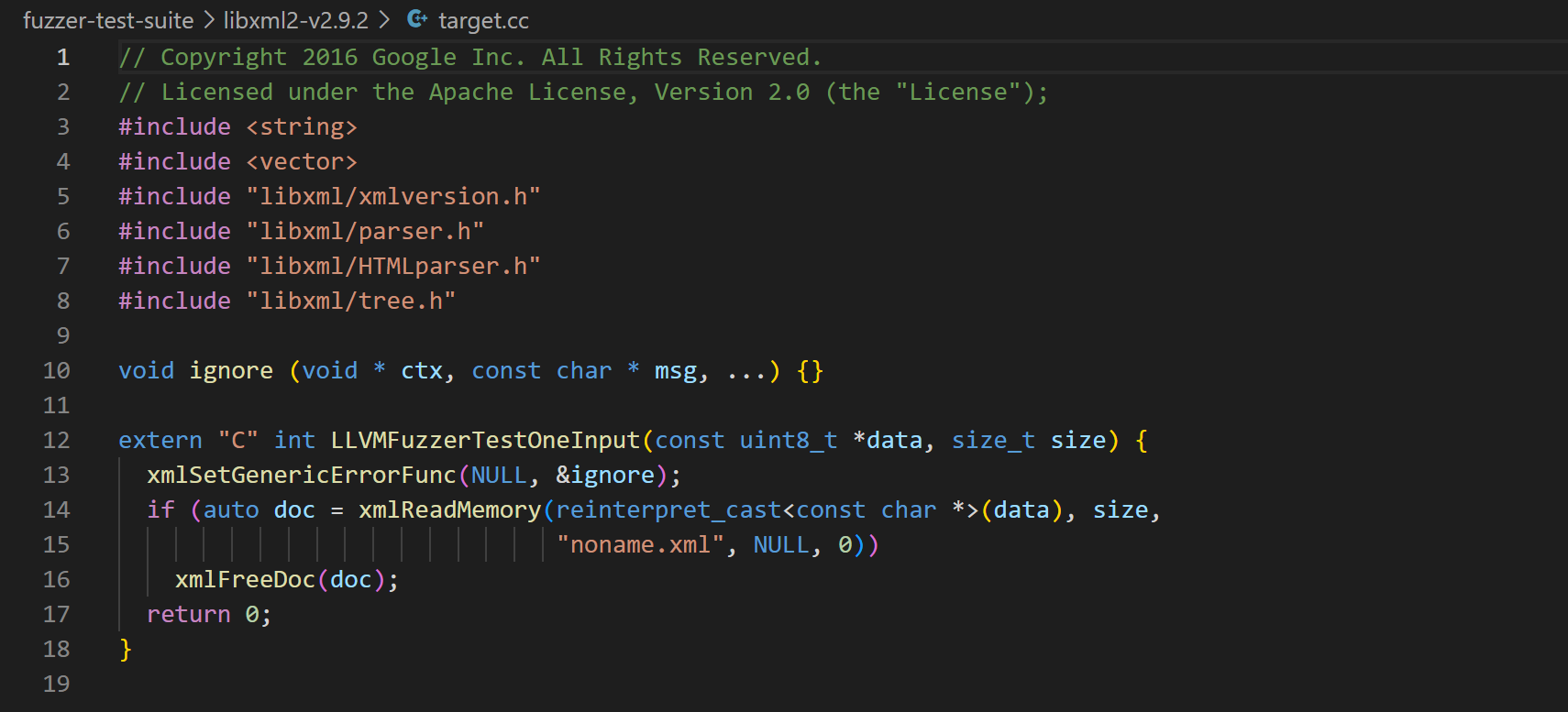
target.cc 内部调用也非常简单,首先将 main() 函数替换为 LibFuzzer 的 LLVMFuzzerTestOneInput() 函数,接下来调用 xmlSetGenericErrorFunc() 函数来进行异常处理,接下来的目标函数 xmlReadMemory() 这个函数是用来解析内存中的 XML 文档并构建树,一参数指向的是 xml 内存数据数组地址,二参数数组长度(官方文档)。由 LLVMFuzzerTestOneInput() 函数随机生成的数据 data 作为 xmlReadMemory() 的一参,size作为二参
构建文档和目标文件解释完了,接下来可以在主目录为本次 libxml2 实验创建一个单独的文件夹,并运行 build.sh 就可以了:
1 | le0n:demo3/ $ ../fuzzer-test-suite/libxml2-v2.9.2/build.sh |
运行时由于需要从 git 上获取项目,所以请保持网络畅通,运行结束将会在当前文件夹下看到存放源代码的 SRC 文件夹、存放库文件的 BUILD 文件夹、LibFuzzer 测试程序 libxml2-v2.9.2-fsanitize_fuzzer 和字典 xml.dict。

比对代码覆盖率
为了展示使用字典能够提升效率的效果,这里可以做一个小实验:两次执行 LibFuzzer 测试程序,第一次不带字典执行,第二次带字典执行。
在相同的时间内 ctrl+c 中断,两次执行中断时基本块覆盖情况:
第一次不带字典执行,运行 15 秒后 ctrl+c 中断。
1 | le0n:demo3/ $ ./libxml2-v2.9.2-fsanitize_fuzzer |

第二次带字典执行,运行 15 秒后中断
1 | le0n:demo3/ $ ./libxml2-v2.9.2-fsanitize_fuzzer -dict=xml.dict |

可以看到添加字典后运行覆盖的基本块要比未使用字典运行覆盖的基本块要多841,所以使用字典一定程度上提高fuzz的效率。libxml2就不跑了,在之前的afl++中已经跑过了